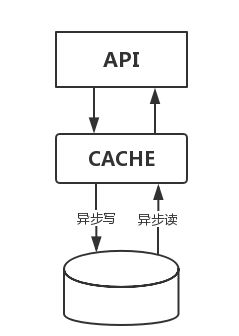
在一个后台系统中,流量控制属于基础组件的功能,其实,在很久之前的通讯时代,流量控制就已经非常成熟了,在路由器交换机上面几乎都有全面的流量控制的解决方案,像QoS这类流量整形的方案,都已经是在网络模型的各个层来进行流量的控制和分发了,可以按照通道,按照端口,IP,MAC,业务类型等各个维度对流量进行整形和控制,比如让语音类的这种高优先级的流量优先通过,而视频聊天这种丢了几帧数据其实没什么影响的低优先级流量慢点通过。对于流量控制,在中后台系统中,一般分成两个类型吧,一种是对连接数进行控制,保证一个机器有可控的连接数,一种是对真实流量的控制,保证机器能通过的流量有多少。流量控制和缓存一样,实际上是对后端的服务起到一个保护的作用,不至于把后端的服务击穿,不同的地方在于缓存保护的主要是读操作,如果用缓存来保护写操作的话,也是一个异步的过程,像下面这个图一样。
而流量控制主要保护的就是写操作了,保证后端的服务别被写请求给击穿,目前我们之所以很少见到流量控制的服务了,主要因为大家优化方向已经朝其他两个方向上来做了。
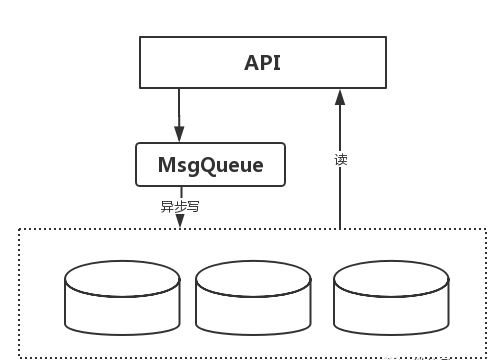
正因为上面的两个原因,现在关注流量控制的人变少了。但有时候,如果后端的服务不能抗住写的压力,并且也没有足够的资源去部署一个消息队列的话(因为消息队列的部署是需要单独的服务器的,还是有成本上的考虑),那么做一个简单的流控系统也基本能满足要求。在本文中,基于连接的流量控制就不是我们讨论的范围了,那个比较简单一点。
我们所说的流量控制,大家比较了解的一般分成两种算法,一种是漏桶算法,一种是令牌桶算法,我们这里并不去深究这两种算法的区别,这个可以在网上很容易找到两种算法的定义和算法描述,这两种流控策略都是来源于路由器的IP层流量控制的算法,我们从另外一个角度来看看流控,我们只借用这些算法的思想,从需求开始,自己一步一步设计一个流控系统。
首先,拿到一个流量控制的需求,需求是入口流量是5MB/s,但是峰值流量是100MB/s,出口的流量要控制在50MB/s以内,数据还不能丢弃,如何来实现这个系统。
第一感觉应该就是下图这个样子,中间有一个内存的FIFO队列,写入方不停的往这个队列里面写入数据,而另一端不停的读取这个FIFO,然后把流量分发到后端上去,这样就完成了数据不能丢弃这个需求,很像前面的那个消息队列,但是慢着,要是前端的写入流量一直保持在峰值的话,那么这内存也爆了,所以除了内存的FIFO以外,还需要一个文件的FIFO来保证在一直是峰值的情况下保证数据的不丢失,你要是问要是硬盘满了怎么办,那我只能呵呵了,当然,也不是没有解决办法,把服务设计成多机模式嘛,这不在本文的讨论范围内。
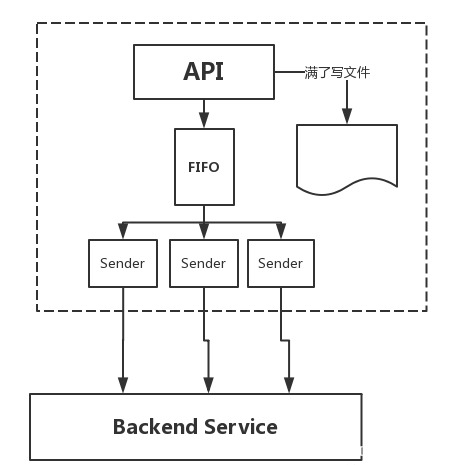
总之,按照上图的设计方法,基本可以满足数据不丢的情况了,对于FIFO的实现方式,可以有很多种,一种是自己开链表,两个指针一头一尾,一边写一边读,如果两边都是多线程的话,锁的设计需要特别注意,尽量减少锁的消耗。还有如果是使用想golang这样的带channel的语言,那么直接丢到channel里面也行,不过这样就是内存不太可控,如果某一个时间段上的数据包都特别大的话,容易造成整体内存的飙升,看具体场景和硬件资源吧,这里就不在赘述了,那么,接下来就考虑流控了。
既然需要流量控制,那么就是发送端在发送数据的时候得知道我现在这个数据能不能发,能发的话可以全发出去还是只能发一部分,最简单的办法就是有个整体的流量控制器,每次发送端发送数据的时候都去询问一下这里流量控制器,现在有多少配额,我能用多少,结构图如下图所示,发送端去询问流量控制器,然后拿到一个发送的配额,按照这个配额进行发送。
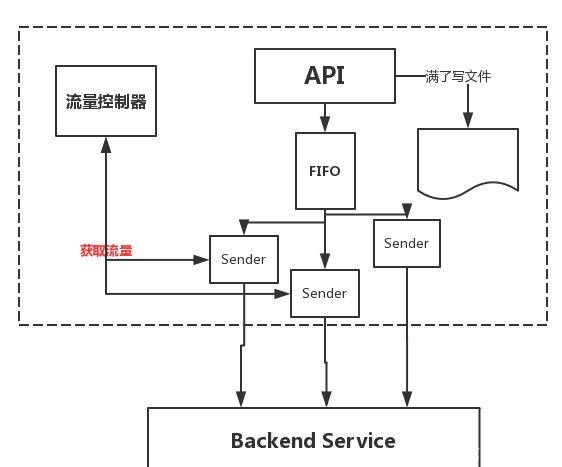
现在FIFO队列也有了,流量控制器也有了,但是最关键的就是流量控制器如何工作的呢?接下来就要设计这个流量控制器了。
对于流控算法的设计,因为是配额制的,所以我们首先得有一个配额的产生机制,比如需求里面说的50MB/s,那就是每秒可以产生50MB的配额,这个简单,你把配额看成一个池子,每秒往池子里加50MB就行了,一旦池子满了,就不加了嘛,这里说的是每秒50MB,实际上加的时候可以按照毫秒来,比如每10毫秒往池子里面加0.5MB,这个用一个线程循环的线程就可以完成。
Quota=0while(1){ sleep(10MS) ; Quota+=0.5;if(Quota>=50){continue;} }
如果是golang的话,也可以把这一部分交给channel来做,写满了就阻塞在channel上了,就像下面这样:
QuotaChannel:=make([]int,100)for{ QuotaChannel<-5 time.Sleep(time.Millisecond*10)}
配额产生搞定了,那么配额的消耗就是这个的反操作嘛,代码就不写了,但是如果是像前面那样使用一个变量的话,那么读写都要加锁,而用golang的channel的话,就不用加锁了,看上去后面的效率更高,但实际上差不多,因为golang的channel在实现上也是加了锁的,而且锁的粒度还比较大,所以用channel并没有什么效率上的提升。整个流控算法实现完以后,就是下图这样样子了。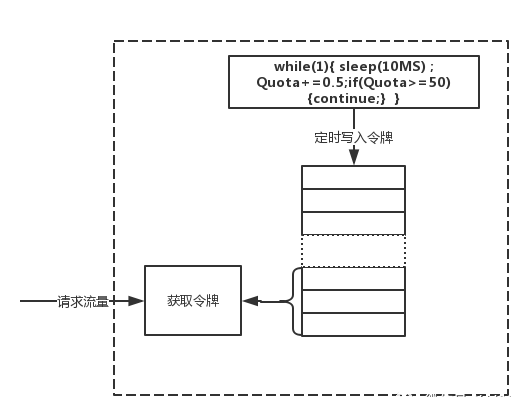 上面实现了一个简单的流控算法,我们没有去深究令牌桶和漏桶算法的具体实现方式,只是按照我们自己的思想去设计了一个流控算法,实际上和令牌桶的思想基本是一致的,大家可以去具体的看看令牌桶,再在算法上做一些优化。
上面实现了一个简单的流控算法,我们没有去深究令牌桶和漏桶算法的具体实现方式,只是按照我们自己的思想去设计了一个流控算法,实际上和令牌桶的思想基本是一致的,大家可以去具体的看看令牌桶,再在算法上做一些优化。
一般的流控设计是跑在TCP层上的,就是能限制TCP层的流量,这样有一个好处就是当你要发送的一个数据包大于50MB的时候,也可以使用这个流控模型,因为在TCP的连接上是可以分包进行发送的,可以拆成多次进行发送,这没有什么问题。如果你的应用是跑在HTTP协议上的,现在很多语言都集成了HTTP的包,直接调用POST请求的API就可以发送数据了,这时候如果出现大于50MB的数据包,就无法进行拆包发送了,出现这种情况,就需要根据实际的业务要求来进行修改和优化了。如果只是偶发情况并且后端服务也可以忍受的话,那就忍了吧,如果不是偶发情况或者后端服务完全不能忍,那你就别用语言自带的HTTP包了,发送的时候自己建立TCP连接自己发送吧,这种改造也不是很复杂。
这篇文章说到的是一个流控的模型,借鉴了令牌桶和漏桶的一些算法,但不要以为流控就是这样的,令牌桶的模型,只是路由器中对IP报文进行流控的一种方式,在路由器上,还有TCP滑动窗口的流控方式,底层还有MAC层的流控方式等等。实际上在TCP层以上是没法做到比较准确的流控的,因为一些协议的开销,TCP自动重传的开销,这个流控器都监测不到,根本就没法准确的流控,只能说是做做简单的流量限制,就拿本文说的例子来说,需求说是需要50MB/s的速度,这是一秒的速度,准确来讲需求方是希望50MB的数据在一秒钟以内均匀的发送出去,而我们的这个流控模型根本无法做到这一点,我们来了一个数据,如果发现池子够大,那么50MB的数据直接就发走了,只是下一次发送的时候我们还需要等0.5秒而已,而均匀的端到端的流控,一般采用的都是TCP的滑动窗口调整来实现,这已经超过本文要描述的了,如果大家感兴趣可以深入去研究一下路由器的流控方式,包括滑动窗口流控啊,MAC层流控【802.1Qbb】啊。通讯领域还是有很多很牛逼的算法的,只是现在通讯领域有些没落了,互联网起来了,做个高可用,分布式就很牛叉一样,实际上和通讯领域的许多东西比起来就是渣渣啊。就如同本文,写了这么多,可能在路由器芯片的功能介绍文档上,就是一行,呵呵。
本文链接: https://dh.7deer.cc/news/41694.html

 举报,我们会及时处理。
举报,我们会及时处理。